
Architecture
The figure below shows the basic analysis workflow supported by Scalasca. Before any performance data can be collected, the target application must be instrumented, that is, probes must be inserted into the code that carry out the measurements. This can happen at different levels, including source code, object code, or library. Before running the instrumented executable on the parallel machine, the user can choose between generating a runtime summary report or an event trace.
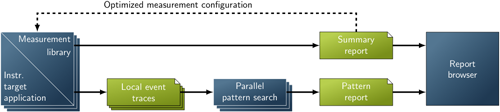
Scalasca's performance-analysis work flow.
When tracing is enabled, each process generates a trace file containing records for its process-local events. To avoid that traces become too large or inaccurate as a result of measurement intrusion, it is generally recommended to optimize the instrumentation based on a previously generated summary report. After program termination, Scalasca loads the trace files into main memory and analyzes them in parallel using as many cores as have been used for the target application itself. During the analysis, Scalasca searches for wait states, classifies detected instances by category, and quantifies their significance. The result is a wait-state report similar in structure to the summary report but enriched with higher-level communication and synchronization inefficiency metrics.
Both summary and wait-state reports contain performance metrics for every combination of function call path and process/thread and can be interactively examined in the provided analysis report explorer along the dimensions performance metric, call tree, and system. In addition, reports can be combined or manipulated to allow comparisons or aggregations, or to focus the analysis on specific extracts of a report. For example, the difference between two reports can be calculated to assess the effectiveness of an optimization or a new report can be generated after eliminating uninteresting phases (e.g., initialization).